
Yapay zekâ, günümüzde ilgi duyulan ve tartışılan ve bir o kadar da az anlaşılan konuların başında geliyor, öyle ki Türk televizyon kanallarındaki tartışma programlarına bile girmiş durumda. Bu alanda son yıllarda yaşanan gelişmelerin temelinde hep aynı yapay zekâ tekniği karşımıza çıkıyor; yaygın tabirle derin öğrenme olarak anılan son nesil yapay sinir ağları. Bu yapay öğrenme teknikleri, işitme, konuşma, görme gibi insan becerilerini taklit etmede son derece başarılı olduklarını herkese kanıtladılar. Google, Facebook, Microsoft gibi şirketler için bu modellerin yeteneklerini daha ileriye götürmek bir prestij yarışına dönmüş durumda. Öte yandan, araştırma süreçleri daha fazla veri odaklı hale geldikçe bilim insanları da derin öğrenmeden bir bilgi keşif aracı olarak faydalanıyorlar. Çocukluk hastalıklarının tıbbi rapor kayıtlarıdan teşhisi, mikroskobik deniz organizmasını tanımlanması, beyin dalgalarından konuşma sentezi ve malzeme özelliklerinin tahmini yazı dizimizi yazmaya başladıktan sonra karşımıza çıkan heyecan verici çalışmalardan sadece birkaçı.
Üçüncü ve son bölümünü okumakta olduğunuz yazı dizimizin ana başlığı, modern bilgisayar bilimleri ve yapay zekâ alanına yön veren en önemli bilim insanlarından biri olan İngiliz matematikçi Alan Turing’in 15 Mayıs 1951’de BBC radyosunda yayınlanan bir konuşmasından geliyor. Amacımız, derin öğrenme sayesinde tekrar alevlenen “düşünen makineler”in insan zekâsına gerçekte ne kadar yaklaştığına dair görüşlerimizi paylaşmak ve derin öğrenme etrafında yaratılan sis perdesini bir nebze olsun aralamak. İlk bölümde genel olarak yapay zekânın ne olduğunu açıklayıp ve bilgisayarla görme üzerinden neden zorlu olduğuna bakmıştık. Bunu takiben yazı dizimizin ikinci bölümünde ise derin öğrenmenin temellerini ve başarılarının ardında yatan nedenleri sizlere aktarmaya çalışmıştık. Yazı dizimizi sonlandırırken bu sefer “Derin modeller insanlar gibi mi akıl yürütüyor?”, “Gerçekten söylendigi kadar başarılılar mı?”, “Hangi noktalarda insanların gerisindeler?” ve “Gelecekte bizleri neler bekliyor?” gibi sorulara odaklanacağız. Bu noktada tekrar ufak bir not düşmekte fayda var, kendi araştırma alanımız yapay zekânın özel bir alt alanı olan bilgisayarla görme olduğu için, ele alacağımız konulara çoğunlukla bu pencereden yaklaşacağız. [1]
Derin öğrenme teknikleri sayesinde bir makinenin önceden programlanmak zorunda kalmadan birçok karmaşık görevi geçmiştekine oranla şaşırtıcı derecede iyi yerine getirebildiğini yazı dizimizin ikinci bölümünde örnekleriyle görmüştük. Peki bu derin modeller ne derecede akıl yürütebiliyor? Şu an Facebook AI Research’de çalışan ve derin ağların eğitimi ile ilgili önemli katkıları olan Léon Bottou, akıl yürütmeyi basitçe şu şekilde tanımlıyor: “Akıl yürütme, yeni bir soruyu cevaplamak için daha önce edinilmiş olan bilgiyi cebirsel olarak manipüle etmek şeklinde görülebilir.” Bu yalın tanım, birinci dereceden mantıksal çıkarım ile olasılıksal çıkarımda izlenen adımları kapsadığı gibi derin ağların gerçekleştirdikleri hesaplamaları da kapsıyor. Bu modeller, bileşimsellik kuralları çerçevesinde belirli bir görevin yerine getirilmesi için eğitilebilir modüllerin nasıl birleştirileceğini öğreniyorlar. Bununla birlikte, günümüzdeki derin öğrenme yaklaşımlarının büyük ölçüde örüntü tanımada uzmanlaşmış devasa modeller olduklarını söylemek zorundayız. Bunda kötü bir şey yok aslında; bir modelin eğitiminde kullanılan öğrenme kümesindeki örneklerin dağılımları ile modelin test edileceği hedef durumların dağılımları birbirine yakınsa modelin genelleme performansının gayet yüksek olacağı aşikâr. Ancak bu varsayım tutmuyorsa işte o zaman bu modellerin barındırdıkları — başarılılarının da anahtarı olan — tümevarımsal önyargılar, onların ilinti ile nedenselliği birbiriyle karıştırmalarına yol açıyor. Şimdi isterseniz birkaç örnek üzerinden bundan ne kastettiğimize bir bakalım.
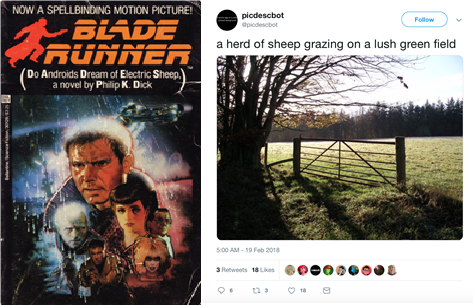
Twitter’da @picdescbot hesabıyla Microsoft’un geliştirdiği bir görüntü altyazılama modelini kullanarak rasgele görüntülere açıklamalar üreten bir robot yazılım var. Alttaki ekran görüntüsü bu robotun girdi olarak verilen bir doğa görüntüsü için otomatik olarak ürettiği açıklamayı gösteriyor: “A herd of sheep grazing on a lush green field (Yemyeşil bir yeşil alanda otlayan bir koyun sürüsü)”. Bilimkurgu yazarı Philip K. Dick’in ünlü kısa romanının adını andırırcasına model bu koyunları düşlüyor. Kuşkusuz bu durduk yere olmuyor, böyle olmasının nedeni eğitim kümesinde yer alan benzer sahnelerin çoğunlukla koyun içermesi. Model görüntü içeriğini tam anlamadan yeşillikler ile bağdaştırdığı “koyun” kelimesini ürettiği açıklamaya ekleyivermiş.
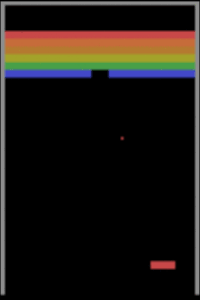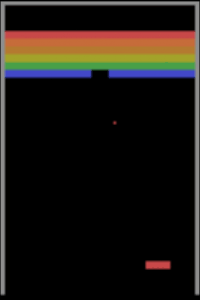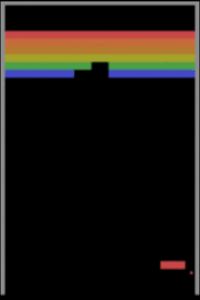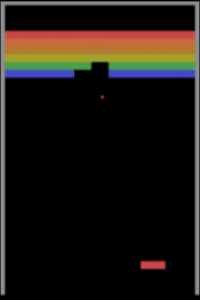
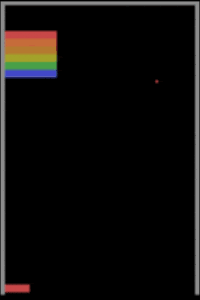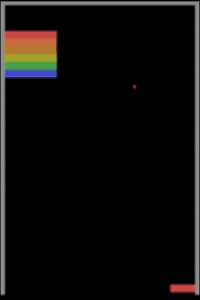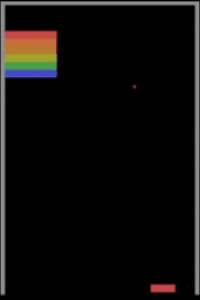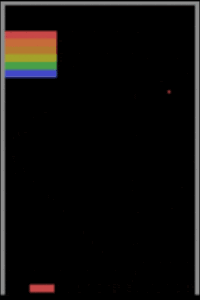
İkinci bir algılama güçlüğü örneği de oyun oynamayı öğrenen makinelerden verelim. Derin pekiştirmeli öğrenmeye dayalı yaklaşımlarının Atari oyunlarından Starcraft gibi zorlu strateji oyunlarına kadar oyun oynamada insan seviyesine çıktıklarından ve hatta bazı oyunlar özelinde insan üstü zekâya ulaştıklarından bahsetmiştik. Peki bu düzeye ulaşmak için milyonlarca kez oyun oynayan (eğitim örneği gören) bu modeller bilişsel yetiler bakımından insanlara gerçekte ne kadar yakınlar? Yakın tarihli bir çalışma, durumun pek de sunulduğu gibi olmadığına işaret ediyor. Şöyle ki Breakout oyununda küçük değişikler olduğunda, mesela raketin Y koordinatı (yüksekliği) değiştiğinde veya ekranın ortasına bir duvar konduğunda insanlar Breakout’un bu varyasyonlarına çok kısa sürede adapte olabilirken DeepMind’in A3C Atari sistemi ekran kayıtlarından görülebileceği üzere tabir yerindeyse sudan çıkmış balığa dönüyor ve bu yeni duruma uyum göstermekte zorlanıyor.
Breakout oyununda yapılan üç ufak değişiklik ve DeepMind’ın A3C modelinin verdiği başarısız tepkiler aşağıdaki görsellerde izlenebiliyor.

Burada örneklediğimiz durumlar sadece bilgisayarla görmeye özel değil elbette. Doğal dil işlemeden bir örnek vermek gerekirse araştırma safhasından başarılı bir ürüne dönüşen ve şu anki sistem başarısını derin öğrenmeye borçlu olan Google Translate’i ele alalım. Bu servis, günde 500 milyon kişiye hizmet verirken günde 100 milyar kelimenin çevrimini gerçekleştiriyor ancak Google’ın düzenli gerçekleştirdiği tüm yöntemsel iyileştirmelere rağmen hala tam anlamıyla mükemmel değil. Geçen yaz İngilizce “köpek” kelimesini 19 kez yazıp Google Translate’e bu anlamsız mesajı Maori’den İngilizceye çevirmesini isteseydiniz karşınıza dini bir kehanet gibi duran şu yazı çıkacaktı:
“Doomsday Clock is three minutes at twelve We are experiencing characters and a dramatic developments in the world, which indicate that we are increasingly approaching the end times and Jesus’ return. (Kıyamet Saati on ikide üç dakika. Dünyada karakterlerin ve dramatik gelişmelerin yaşandığını gösteriyor; bu, bitiş zamanlarına ve İsa’nın geri dönüşüne gittikçe daha fazla yaklaştığımızı gösteriyor.)”
Neyse ki Google Translate artık bu kehanetinden vazgeçmiş durumda. Şaka bir yana derin öğrenme modellerinin en büyük sorunu, beklenmedik bir girdi ile karşı karşıya kaldıklarında beklenmedik şekillerde davranmaları. Peki Google Translate’in böyle bir çeviride bulunmasının nedenini merak ediyorsanız onun da basit bir açıklaması var. Makine çevrimi modellerinin eğitimi birbiriyle aynı anlama sahip farklı dilden cümleler üzerinden gerçekleştiriyor ve Maori gibi düşük kaynaklı diller için bu tarz bir paralel veriyi elde etmenin en kolay yolu İncil gibi kutsal kitapların çevirileri kullanmaktan geçiyor ve tabi bu durum modellerde böyle istenmedik sonuçlar doğurabiliyor.
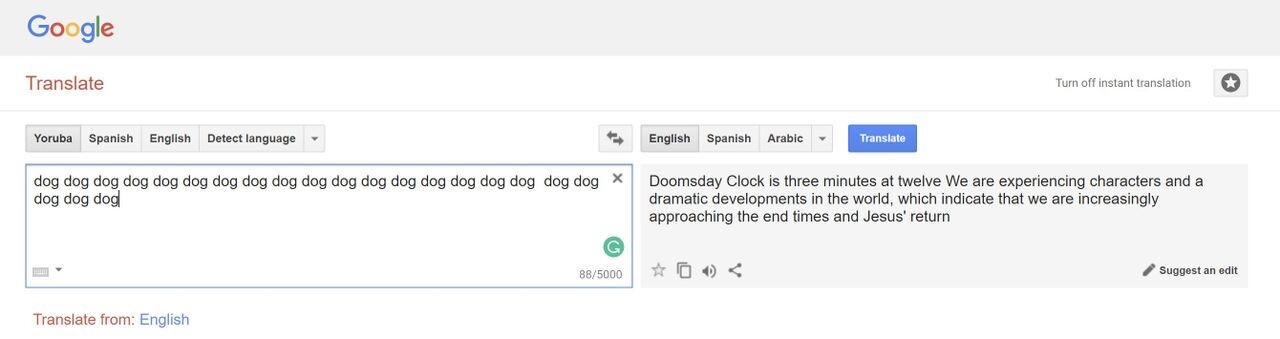
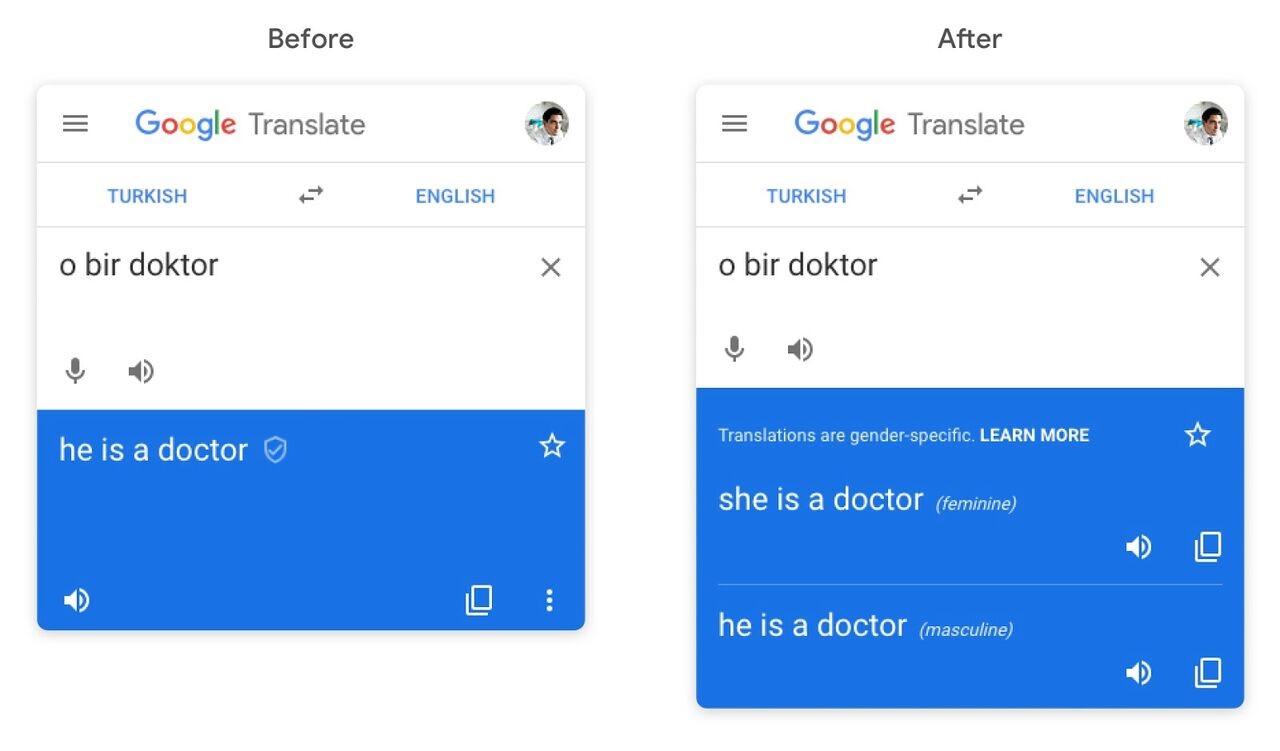
Google Translate bu örnek için çeviri yapmak yerine dini kehanetlerde bulunuyor.Ama konu Google Translate olunca pratikte yaşanan en ciddi problem dillere özgü var olan sosyal önyargılar. Yapay öğrenme modelleri insan faktörünü aradan çıkartıp bir sürü görevi otomatik gerçekleştirdiği için pek çok kişide bu yaklaşımların nesnel kararlar verdiği algısı hâkim. Halbuki yola çıkarken öğrenme kümesi olarak seçtiğiniz veri önyargılar barındırıyorsa bu modelinizin de önyargılı olmasını beraberinde getiriyor. Örneğin yandaki şekilde soldaki çeviriye bakacak olursak Türkçe asıl metinde cinsiyet bilgisi bulunmamakla birlikte, bu cümlenin İngilizce çevirisi doktorun erkek olduğunu varsaymış. Google, bu problemin önüne çok kısa bir süre önce eklediği bir özellikle ile cinsiyet tercihlerine göre alternatif çeviriler sunarak geçmeye çalışıyor.
Hemen bilgisayarla görmeden gerçek dünyadan bir başka örnek olay ile devam edelim. Microsoft, IBM gibi firmaların piyasaya sundukları ticari yüz tanıma sistemleri iş koyu tenli kadınları tanıma olunca ciddi anlamda başarısız oluyor. Daha önce belirttiğimiz üzere, bu cinsiyetçi ve ırkçı kararlar ile ilgili suçlanması gereken öğrenme algoritmaları veya öğrenilen modeller değil, bilhassa eğitimde kullanılan verinin kendisi. Bu noktada yapay zekâ etiği, algoritmik tarafsızlık, algoritmik şeffaflık, vb. konular giderek daha fazla önem kazanan alanlar ve bu konularda araştırmacılara büyük sorumluluklar düşüyor.

Gelecekte Bizleri Neler Bekliyor?
Yukarıda verdiğimiz örneklerin tamamı zekânın sadece örüntü tanıma demek olmadığını bizlere gösteriyor. Yapay zekâya ulaşmak insan zekâsını anlamaktan geçiyor diye düşünenlerdenseniz bu konuda MIT, Harvard ve New York Üniversitesi’nden araştırmacılar tarafından kaleme alınan Building Machines That Learn and Think Like People (İnsanlar Gibi Öğrenen ve Düşünen Makineler Geliştirmek) başlıklı çok çarpıcı bir makale var. İsterseniz şimdi bu makaleden hareketle bu konudaki görüşlerimizi paylaşalım. Öğrenme dediğimiz eylem bir anlamda dünyayı modelleme sürecini de içermeli. Bu açıdan bakacak olursak öğrenmeye dayalı modellerin belli nitelikleri sağlaması önemli. Öncelikle bu modellerin gördüklerini ve kararlarını açıklayabiliyor olmaları şart ki bu da derin modellerin en zayıf kaldığı yönlerden biri. Bu modeller, evet bir karar veriyorlar, ancak onları bu karara iten etkenlerin neler olduğunu rahatlıkla anlayamıyoruz. Bu kapalı kutu modeller genellikle yorumlanabilir olmaktan uzaklar. Bu bağlamda bu modellerin gerçekten sağduyuya sahip olup olmadıklarını anlamanın yolu onları, onların karar alma süreçlerini açıklamaktan geçiyor. Özellikle son yıllarda araştırılmaya başlanan ve giderek önem kazanan bir konu yorumlanabilir modeller geliştirmek. Bunun bir yolu bu karmaşık modelleri insan görme sistemine benzer şekilde nöral dikkat mekanizmaları ile donatmak ki aşağıdaki resimde bir örneğini görebileceğiniz üzere bir model verdiği bir karar ile ilgili olarak girdi görüntüsünde nelere odaklanmış onu görebilelim ve modeli buna göre yorumlayabilelim.

Yine öğrenme açısından incelenmesi gereken bir diğer nokta, derin modellerin problem çözme ve planlama açısından sınırlarını zorlamak. Görsel akıl yürütme, bu yönde son yıllarda ele alınmaya başlanan bir araştırma konusu. Yandaki resim bu problem için incelenen veri kümelerinden birisi olan CLEVR’dan örnek bir görüntü ve o görüntü ile ilgili sorulan bir soruyu gösteriyor. Görüntü basit geometrik şekillerden oluşuyor denebilir ama böyle bir sorunun doğru yanıtlanması nesnelerin bulunup konumlarının tespit edilmesinin yanı sıra fiziksel özelliklerinin ve nesneler arasındaki ilişkilerinin sorgulanmasını da gerektiriyor.

İnsanlar gibi akıl yürütebilen yapay modellerin geliştirilmesi, araştırma grubu olarak bizlerin de ilgisini çeken bir konu. Bu yönde gerçekleştirdiğimiz bir çalışmamızda RecipeQA adını verdiğimiz, yemek tariflerinden oluşan ve literatürdeki benzerlerinden yazılı ve görsel kipteki bilgilerin birlikte işlenmesini gerektirmesi yönünden ayrışan yeni bir veri kümesi önerdik. Örneğin alttaki resimde verilen doğru sıraya dizme sorusu biz insanlar tarafından yanıtlanması kolay bir soru ama bir makinenin bu soruya doğru cevabı verebilmesi için sunulan görüntüler ile kahve pişirme tarifinin adımlarını kafasında eşleştirmesi ve bu adımlar arasındaki zamansal ilişkileri kavraması gerekiyor. İnsanların RecipeQA’deki soruları yanıtlama başarıları dikkate alındığında ilk sonuçlarımız, mevcut derin modellerin hayli zorlandıklarını ve bu görevin üstesinden gelebilecek şekilde daha etkin akıl yürütebilen modellere ihtiyaç olduğunu ortaya koyuyor.

Son dönemde derin öğrenme üzerine çalışan araştırmacıların ilgisini çeken, görsel akıl yürütme ile ilişkili bir diğer araştırma konusu, hesaplamalı nörobilim, bilişsel bilimler ve yapay zekânın tam kesişiminde yer alan sezgisel fizik (intuitive physics). İnsanlara fiziksel sistemler ile ilgili sorulan bir soruyu kalem ve kâğıt kullanarak cevaplamaları istendiğinde bu kişiler genellikle doğru yanıt veremezlerken toplanan davranışsal veriler insanların aslında çeşitli fiziksel olayları bilişsel düzeyde anlamak için sezgisel bir fizik motoru kullanıyor olabileceğini gösteriyor. Örneğin, yolda giderken zıplayan bir top gördüğümüzde topun yönü ve hızı hakkında sezgisel çıkarımlarda bulunabiliyoruz. Dünyanın fiziksel düzeyde nasıl işlediği aslında sağduyu olarak adlandırdığımız ve makineler açısından öğrenilmesi en zor olan bilgi türünün bir parçası. Bu konudaki çalışmalara bir örnek verelim. Geçtiğimiz Eylül ayında sunulan bir çalışmada, benzetilmiş veriler kullanarak çarpışmaların etkilerini tahmin edebilen bir sezgisel fizik modeli geliştirildi. Bu model, çarpışma anı öncesinden alınan ilk dört kareden yola çıkarak bu gözlemler ışığında sürtünme, kütle, hız gibi fiziksel özellikleri kestirip çarpışma sonucunu kestirebiliyor.

Yukarıda değindiğimiz akıl yürütme ve sezgisel fizik konuları yapay öğrenme bağlamında tabi ki önemli ama düşünüldüğünde görece çok kısıtlı senaryoları ele alıyorlar. Hiç karşılaşılmamış bir durumla başa çıkabilmek daha önce dile getirdiğimiz üzere yaşadığımız dünyanın bir modelini kurmayı gerektiriyor ki düşünecek olursanız gerçek hayatta gelecek genellikle belirsiz bir yapıda ve birçok farklı olasılık söz konusu. Bu anlamda özellikle son yıllarda yapay öğrenme açısından heyecan uyandıran çalışmaların büyük bir kısmı gözetimsiz öğrenme (unsupervised learning) olarak adlandırılan, etiketsiz veriden bu verideki örneklerin yaşadığı uzayı daha iyi anlamamıza olanak veren çalışmalardan oluşuyor. Bunlar içinde şu sıralar belki en medyatik olan gözetimsiz öğrenme modeli de “çekişmeli üretici ağlar” (generative adversarial networks). Örnek verilerden yola çıkarak görmediğimiz şeyleri de hayal etmemize imkân veren çekişmeli üretici ağlar, aşağıdaki görüntülerin gösterdiği gibi bu alanda çığır açan nitelikteki sonuçları birkaç yıl içinde almamızı sağlamış durumda. Bilgisayarla görme özelinde bu modeller üzerinden gerçekçi duran sentetik görüntüler üretmek, bunlara dayalı uygulamalar gerçekleştirmek birçok araştırmacının ilgisini çekiyor.

Video, istediğiniz özellikte gerçekci insan yüzleri üretmeye imkân veren StyleGAN
modelini gösteriyor.
Bu üretici modellerin olası kullanımlarına bir örnek verecek olursak grubumuzca gerçekleştirdiğimiz bir çalışmamızda, dış mekân görüntülerinin gece, günbatımı, sis, bulut gibi geçici görsel niteliklerini kolayca değiştirmeye imkân veren bir sistem önerdik. Bu sayede, örneğin güneşli bir günde çekilmiş bir görüntünün bulutlu veya sisli bir havadaki halini ürettikten sonra ilgili görünümü girdi görüntüsü üzerine kolaylıkla taşıyıp istenen nitelikte görüntüler elde edebiliyoruz.

Böylece üç bölümlük yazı dizimizin sonuna gelmiş olduk. Umarız yazma aşamasında bizler için olduğu kadar sizler için de burada anlattıklarımızı okumak hoş bir serüven olmuştur. Derin öğrenme teknikleri sayesinde son 5-6 yılda yaşanan gelişmeler ve bu gelişmelerin aynı hızda diğer bilim dallarına ve günlük hayatımıza katılması yapay zekâ etrafında çok büyük bir heyecan dalgası oluşturmuş durumda. Bu ilgi elbette bu konuda çalışan araştırmacılar olarak bizleri çok mutlu ediyor ama burada ciddi bir risk de mevcut. Claude E. Shannon’ın 1956 yılında yazdığı, “The Bandwagon” adlı yazısında enformasyon kuramı için yaptığı uyarıya benzer şekilde modaya uyup bu vagona atlamadan önce varolan modellerin matematiksel temelleri ve sınırlarını tam olarak anlamamız gerekiyor. Bu anlamda, bu yazı dizimizin amaçlarından biri de günümüzdeki modellerin eksik parçalarını gösterip daha fazla ilerleme kaydetmek için daha nelere ihtiyaç duyulduğuna dikkat çekmekti. Derin öğrenme bundan 10 yıl sonra hala bugünkü kadar yaygın olarak kullanılacak mı? Gary Marcus ve Judea Pearl gibi önemli isimlerin eleştirileri doğrultusunda derin modellerin geçmişteki klasik yaklaşımlarında kullanılan ve üst düzey sembolik temsillerin işlenmesine dayanan sembolik yapay zekâ ile birliktelikleri mümkün olacak mı? Bunu şimdiden tahmin etmek çok zor.
Aykut Erdem (Hacettepe Üniversitesi Bilgisayar Mühendisliği Bölümü öğretim üyesi)
Erkut Erdem (Hacettepe Üniversitesi Bilgisayar Mühendisliği Bölümü öğretim üyesi)
[1] Bu yazı dizisinin temeli 6 Mayıs 2018’de Boğaziçi Üniversitesi’nde düzenlenen International Symposium on Brain and Cognitive Science 2018 etkinliğinde Ethem Alpaydın moderatörlüğünde gerçekleşen panelde Aykut Erdem’in sunumuna dayanıyor.




{kind=link}