
31 Aralık 2019’da Çin’de yeni bir virüsün ve hastalığın varlığı duyurulduğundan beri COVID-19 hastalığı ve buna neden olan SARS-CoV-2 (nCoV-19) virüsü hakkında çok şey öğrendik.
Ocak 2020’nin başlarında, Wuhan’daki hastaların akciğerlerinden elde edilen sıvı örneklerinden virüs izole edildi ve 12 Ocak’ta tüm dünyayla paylaşıldı [1]. Virüsün daha önce SARS, MERS gibi virüslerin de içinde yer aldığı koronavirüs ailesine (CoV) ait olduğu anlaşıldı.
Ancak, SARS-CoV-2 virüsü diğer aile üyeleri ile benzerlik gösterse de virüsün genetik yapısı yeniydi. Bu doğrultuda, bilim insanları, COVID-19 hastalığına neden olan SARS-CoV-2 virüsünün kökeni, yayılımı, hastalık oluşturma yeteneği gibi özelliklerin aydınlatılması amacıyla virüsün genetik yapısı üzerinde yoğun bir çalışma sürecine girdiler.
Bilimsel yayın sayıları – PubMed
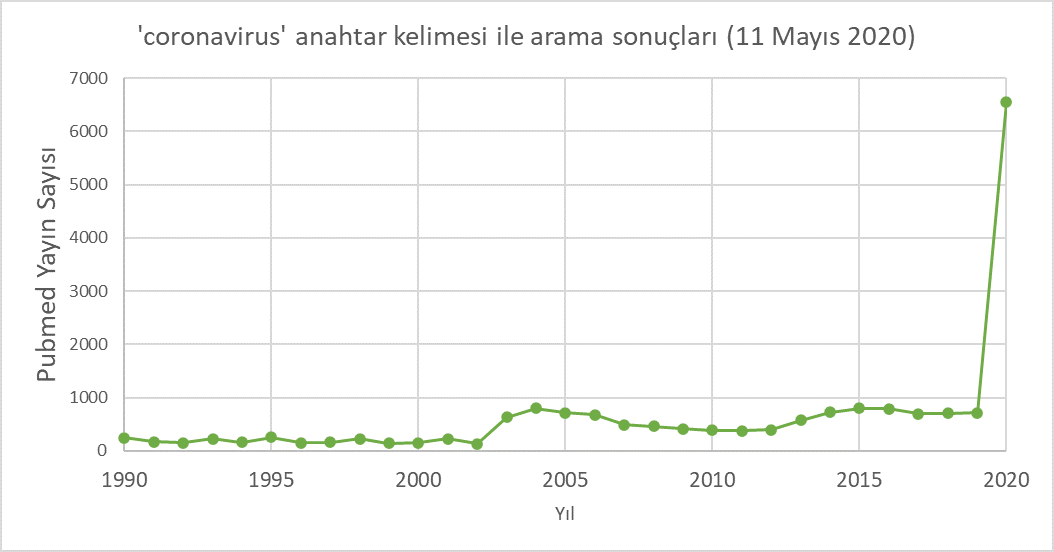
Bu süreçte yalnız virüsü değil hastalığı ve insan vücuduna etkilerini anlamak için de, olası tedavi yöntemlerinin etkilerini anlamak için de birçok çalışma yapılıyor. Şekil 1, PubMed arama motorunda “coronavirus” anahtar kelimesiyle yapılan aramada çıkan yayın sayılarının senelere göre değişimini gösteriyor. Grafikte SARS (2003) ve MERS (2016) salgınlarının neden olduğu yükseltiler belirgin olsa da bugün tüm dünyayı etkileyen bir salgınla karşı karşıyayız ve bilim dünyası tüm kaynaklarını bu salgının durdurulmasına yönlendirmiş durumda, 2020’nin ilk aylarındaki yayın sayısı da bu salgının etkisini gözler önüne seriyor [2].
PubMed, yaşam bilimleri ve biyomedikal konulardaki yayınların bulunduğu MEDLINE (Online Tıbbi Literatür Analizi ve Erişim Sistemi) veritabanına erişen ücretsiz bir arama motorudur. Pubmed arama motoru, biyomedikal ve genomik bilgilere erişim sağlayan, Ulusal Biyoteknoloji Bilgi Veritabanı (NCBI) çatısı altında yer alır.
Genom nedir? SARS-CoV-2 genom verilerinin paylaşımı – GISAID
Genom deyince bir organizmanın genetik bilgisini taşıyan genlerin tamamından bahsediyoruz (birçok canlıda DNA, koronavirüs gibi virüslerde RNA genomu oluşturuyor). Her genom o organizmayı yeniden oluşturmaya yarayan bilgiyi taşıyor. İnsanlarda 3 milyar DNA parçası (baz çifti) var, SARS-CoV-2’de ise 29 bin kadar RNA parçası var.
COVID-19 hastalarından alınan virüs örnekleri açık erişimli veritabanlarına yükleniyor ve bilim insanları buradaki bilginin okunması için ileri teknolojiler kullanıyor. Bu teknolojiler içerisinde genetik mühendisliği teknikleri ve yazılım destekli biyoinformatik analizler de var.
Bilimsel çalışmalarından elde edilecek olan genom verileri oldukça önemli çünkü SARS-CoV-2 genom yapısının anlaşılması COVID-19 hastalığını anlama, önleme ve tedavi etme yönünde (ilaç ve aşı üretimine) katkı ve kolaylık sağlayacak. COVID-19 salgınının başlamasından ve hastalığın pandemi olarak tanımlanmasından bu yana, dünyadaki laboratuvarlar, eşi görülmemiş bir hızda viral genom dizisi verisi üretiyor ve yeni hastalığın anlaşılmasında ve aday tıbbi önlemlerin araştırılmasında ve geliştirilmesinde gerçek zamanlı ilerleme sağlıyor.
Salgının başında virüsün genom dizilimi Çinli bilim insanları tarafından çok hızlı bir şekilde dünyayla paylaşıldıktan sonra, virüsün dünyada yayılmasıyla beraber, birçok ülke virüs genomunu dizileyerek büyük bir veritabanı oluşmasına katkıda bulundu. SARS-CoV-2’nin 17 bin’den fazla viral genom dizisi, GISAID veritabanı yoluyla görülmemiş bir hız ile paylaşıldı.
Türkiye’den paylaşılan ilk SARS-CoV-2 genom dizisi Türkiye Sağlık Bakanlığı tarafından GISAID veritabanı aracılığı ile 25 Mart 2020 tarihinde açık erişime sunuldu [3].
GISAID (tüm grip hastalığı verilerini paylaşmaya yönelik küresel girişim olarak bilinir) girişimi, araştırmacıların virüslerin nasıl evrimleştiğini, yayıldığını ve salgın haline geldiğini anlamalarına yardımcı olmak için tüm grip virüs genom dizilerinin, insan virüsleriyle ilişkili verilerin, kuş ve diğer hayvan virüsleri ile ilişkili coğrafi ve türe özgü verilerin uluslararası paylaşımını teşvik eder.
Dünyanın dört bir yanındaki laboratuvarlar genom dizilerini GISAID [3] yoluyla paylaşmaya devam ediyor. Şimdiye kadar paylaşılan genom veri sayıları ülke bazında Şekil 2’te gösteriliyor
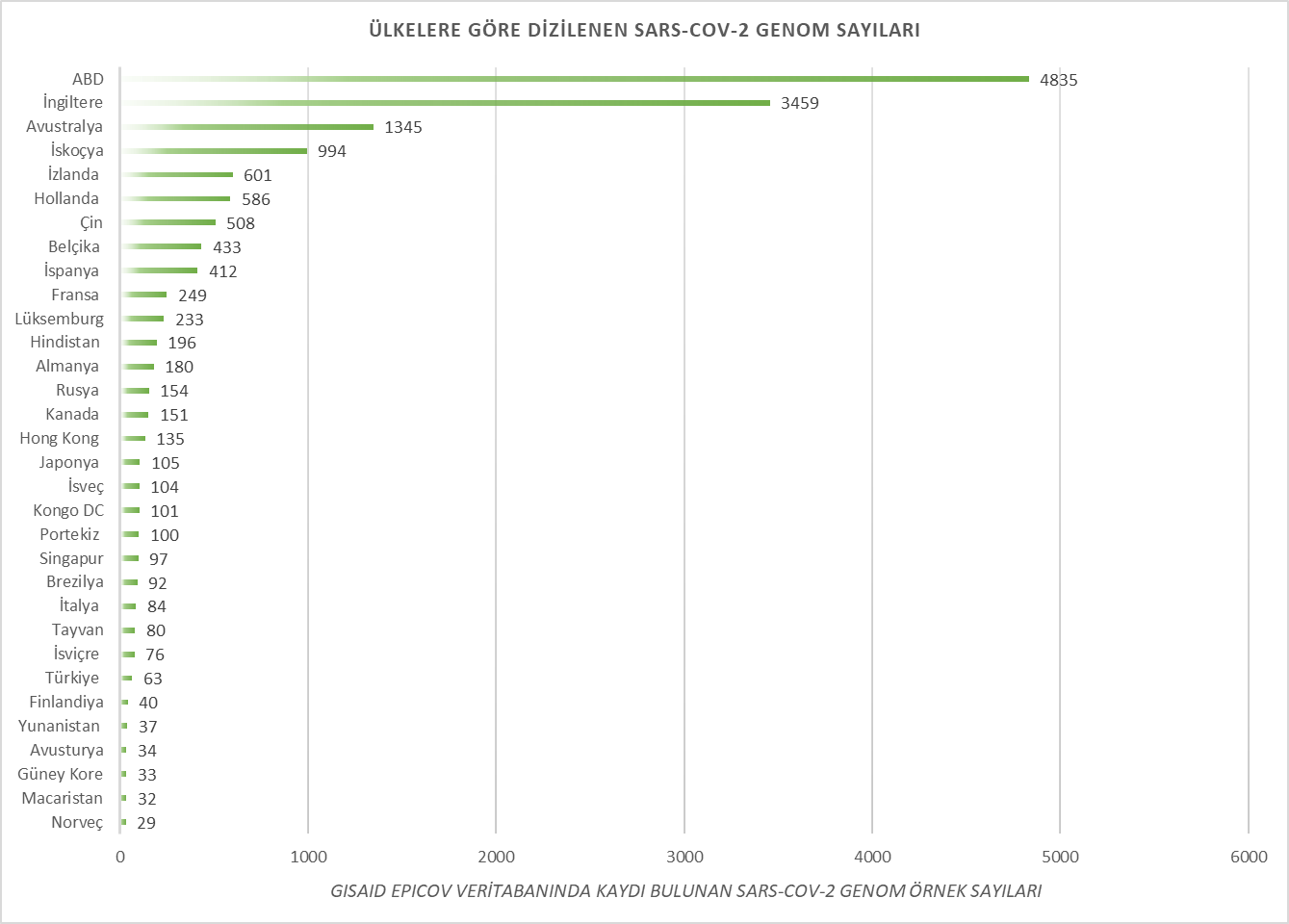
Farklı ülkelerden paylaşılan SARS-CoV-2’un genom dizileri, tanı testlerini tasarlamak ve değerlendirmek, devam eden salgını izlemek ve potansiyel müdahale seçeneklerini belirlemek için önemli.
Ayrıca, farklı hastalardan, hayvanlardan, yerlerden veya zaman periyotlarından elde edilen birden fazla virüs genomu karşılaştırılarak virüsün genetik bilgisinde yer alan şifrelerin gizemli anlamı çözülebilir. Özetle, virüsün nereden kaynaklandığı, hayvanlardan insanlara nasıl bulaştığı, ne kadar hızlı değiştiği ve bu değişikliklerin enfeksiyonları nasıl etkilediği gibi soruların yanıtlarına genom karşılaştırmaları ile ulaşılabilir.
GISAID’de toplanan Sars-CoV-2 genom verilerinin analizi – NextStrain
12 Ocak’ta paylaşılan SARS-CoV-2 genomu sonrası süreçte yeni veriler GISAID veritabanında açık erişime sunuluyor ve veriler açık kaynaklı Nextstrain platformunda analiz ediliyor [4].
Nextstrain, patojen genom verilerinin bilimsel ve halk sağlığı potansiyelinden yararlanmak için kurulmuş olan/çalışan/kullanılan açık kaynaklı bir platform. Topluluk tarafından kullanılmak üzere güçlü analitik ve görselleştirme araçlarının yanı sıra halka açık verilerin sürekli güncellenen bir görünümünü sağlıyor. Amacı salgının yayılımını anlamak ve salgına karşı alınan tedbirleri iyileştirmek. Nextstrain, SARS-CoV-2 genomları paylaşıldığında, analizler ve durum raporları sağlıyor. Raporlar haftalık olarak güncelleniyor.
Türkiye’den 25 Mart 2020 tarihinden itibaren toplam 63 adet SARS-CoV-2 genom dizisinin farklı kurum ve laboratuvarlar tarafından açık erişimde paylaşıldığını görüyoruz. Elbette bu sayı yeni veriler geldikçe gerek GISAID gerek Nextsrain veritabanlarında hemen güncelleniyor. Şimdi görsel açıdan ve yayılım bakımından farklı ülkelerden ve Türkiye’den gelen genom verilerini Nextstrain veritabanından göstermeye çalışalım.
Nextstrain platformunda halka açık toplam 5000’ün üzerinde SARS-CoV-2 genom dizisi analiz edilmiş durumda. Farklı ülkelerden ve Türkiye’den paylaşılan tüm bu genomlar birbirleriyle karşılaştırılarak, SARS-CoV-2’nin dünya çapında nasıl hareket ettiği ve yerel olarak nasıl yayılım gösterdiği karakterize edebiliyor. Dahası, yeterli sayıda dizilenmiş genom ile, bir virüs ailesinin mutasyon geçmişinin, yani virüsün gen yapısında meydana gelen değişikliklerin, bir filogenetik (soy) ağacını yeniden yapılandırmak mümkün olabiliyor. Bu şekilde virüsün evrimsel yayılımı ve şimdiye kadar oluşmuş yeni mutasyonları da tespit etme olanağı buluyoruz.
Bir filogenetik (soy) ağacı, farklı biyolojik türler veya ortak bir atası olan diğer varlıkların arasındaki evrimsel ilişkileri gösteren bir grafik ağaçtır. Bir filogenetik ağaçta, iki dalın ayrıldığı her bir düğüm noktası altsoyların ortak atasını temsil etmektedir. Filogenetik ağaçlar genetik epidemiyoloji hakkında önemli bilgiler elde etmemizi sağlarlar.
Genetik epidemiyoloji kavramı, 20. yüzyılın ilk yarısında, Newton E. Morton tarafından, “akrabalar arasında, hastalıkların nedenleri, yaygınlığı, dağılımı ve kontrolünü inceleyen ayrıca toplumlarda hastalıkların genetik nedenlerini araştıran bilim” olarak tanımlanmıştır; Morton NE. Foundations of Genetic Epidemiology. J Genetics 1986; 65(3):205-212.
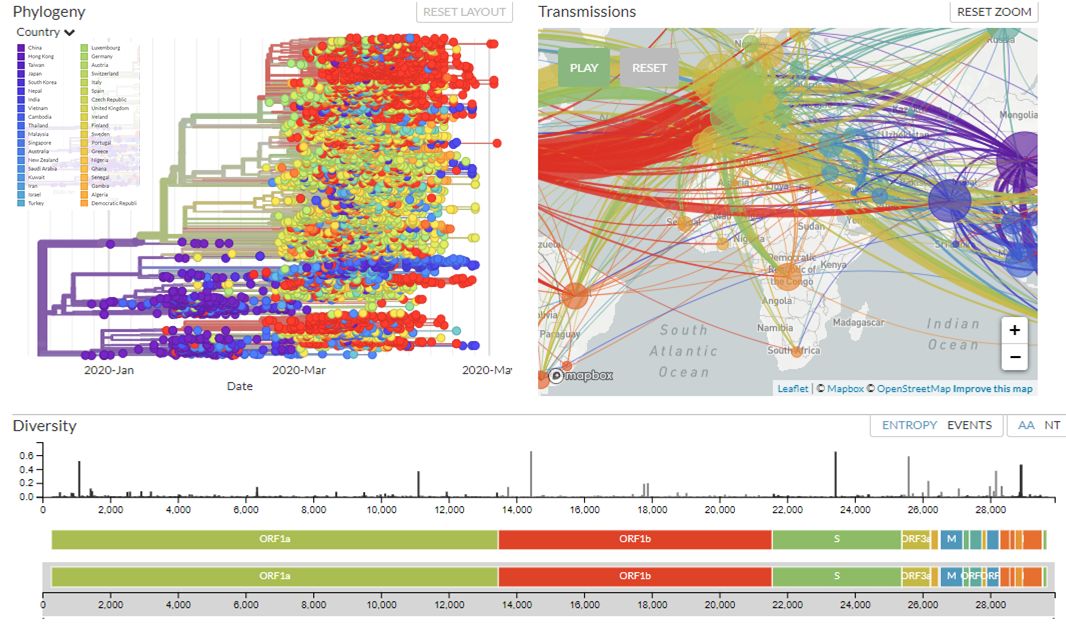
Şekil 3’ü özetlemek gerekirse: Sol üst tarafta farklı ülkeler tarafından paylaşılan SARS-CoV-2 mutasyonların renkli dairelerle gösterildiği bir filogenetik (soy veya bulaşma) ağacı görüyoruz. Her bir daire bir vakayı (enfekte olmuş bir bireyi ve mutasyonları), yatay (x) ekseni zamanı gösteriyor. Herhangi bir ölçüm birimine sahip olmayan ağacın dikey (y) ekseni ise ağaç üzerinde yer alan her şeyi görmemize kolaylık sağlıyor. Aralarında bağlantı olan örnekler yayılım kaynağı ortak olanları temsil ediyor. Bu bağlantılar örneklenmiş vakalardaki mutasyon örüntülerinin analiz edilmesiyle anlaşılabiliyor. Örneklenmiş virüsler arasındaki genetik ilişkiler, spesifik yayılım tarihleri ve coğrafi yayılımın yeniden yapılandırılmasıyla ilgili tahminleri göstermeyi amaçlıyor.
Şekil 3’ün sağ tarafında ise bir harita görüyoruz. Harita ile filogenetik ağaç arasındaki ilişkiye baktığımızda ağacın her bir örneğin konumuna (ve her bir düğüm noktasının tahmini konumuna) göre renklendirilmiş versiyonunu görüyoruz. Nexstrain veritabanına giriş yaparak harita üzerinde yer alan “Play” butonuna basarsanız virüsün salgın süresince tahmin edilen yayılımını gösteren bir animasyonu izleyebilirsiniz.
Haritada 6 kıta, 74 ülkeden alınan örneklerden elde edilen genom dizileri yer alıyor. Harita dünyanın güney bölgelerden az sayıda genomik dizi verisi geldiğini gösteriyor. Ancak bunun nedeni, COVID-19’un bu bölgelerde yayılmamış olması veya bu alanların önemli olmaması değil, bu bölgelerden henüz veri paylaşılmaması. Haritadaki her dairenin boyutu o bölge hakkında sahip veri bilgisini gösteriyor, salgının boyutunu değil [2,3].
Şekil 3’ün altında ise SARS-CoV-2 genomundaki mutasyonları gösteren “Diversity” (genetik çeşitlilik) isimli çubuklu bir grafik görüyoruz. Çeşitlilik panelinde yatay eksen virüs genomundaki her bir bölgeyi gösteriyor (SARS-CoV-2 genom boyutu ~30.000 bç olup 11 genden oluşuyor). Dikey eksen ise her bir bölgede ne kadar çeşitlilik olduğunu gösteriyor. SARS-CoV-2 genomunda yer alan mutasyonlar genomik diziler arasındaki ilişkiyi belirleyebiliyor ve filogenetik ağacın oluşmasında büyük bir rol oynuyor; aksi halde bu ağacın çizilmesi mümkün olmayacaktı [3]. Şekil 3 tüm global verileri içerdiğinden görselin ne anlama geldiğini özetlememizin nedeni Türkiye verilerini gösterirken kolaylık sağlayacak olması.
Eldeki veriler ve Türkiye
GISAID veritabanı aracılığı ile Mart ayından itibaren Türkiye’den 63 genom dizisinden 61’in nextstrain platformunda paylaşıldığını (Şekil 4) görüyoruz [2,3].
Burada önemli bir uyarıda bulunmalıyız: Bu veriler salgının pek çok özelliğine dair sonuçlar çıkarılmasına ve yayılımın takip edilmesine olanak sağlasa da, hem dünya hem de Türkiye’den sağlanan genom verisi kesin sonuçlara varmak için yeterli değil. Bu yazıda Nextstrain’in eldeki kısıtlı veriyle gösterdiği analizden kısaca bahsedeceğiz fakat gelecekte daha fazla verinin eklenmesiyle bugün gördüğümüz tablo tümüyle değişebileceği için çıkan sonuçların yalnızca eldeki veriler ile sınırlı olduğuna dikkat çekiyoruz.
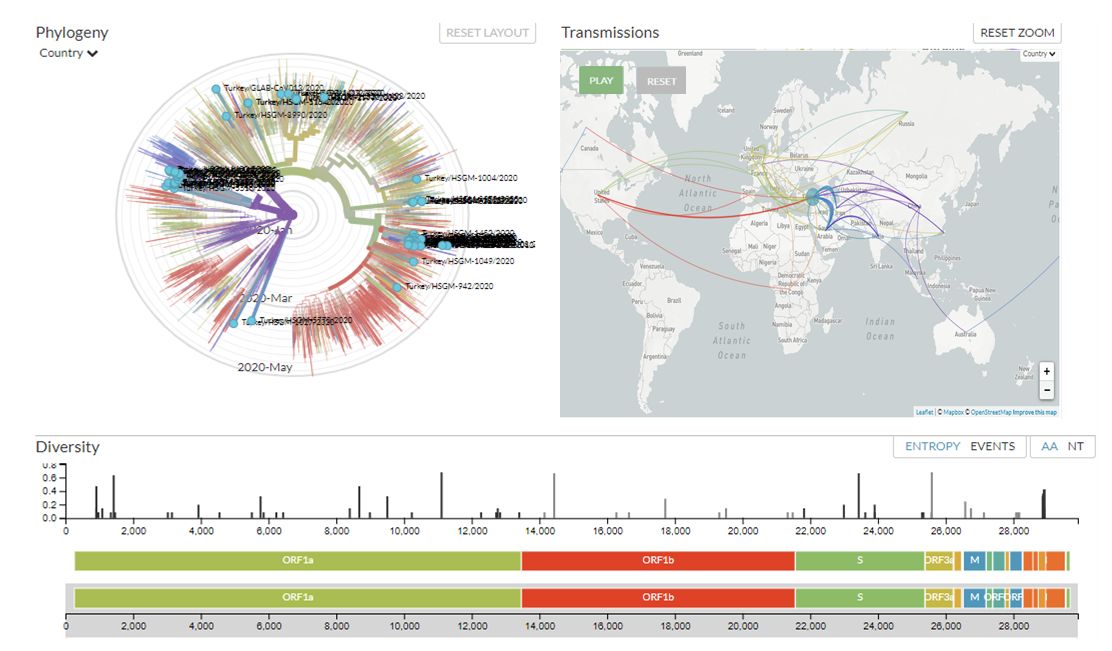
Şekil 4’te sol tarafta Türkiye’nin filogenetik (soy) ağacını görüyoruz. Görselden görmek kolay olmadığından filogenetik ağaçta yer alan mutasyonların SARS-CoV-2’nin ORF1a, ORF1b, ORF3a, ORF8, ORF14, S ve N gen bölgelerinde tespit edildiğini söyleyebiliriz. Bu gen bölgelerinden S geni bölgesi SARS-CoV-2 virüsünün çıpa (spike) proteinini kodlayan bölge olması ve bu proteinin yapısı itibariyle virüsün konakçı hücreye girişini kolaylaştırabileceği daha önce yayınlamış makalelerde tartışılmıştı [5]. Paylaşılan diğer genom verilerinde ise herhangi bir yeni mutasyon tespit edilmediği görülüyor.
Elde edilen yeni mutasyonlar üzerinden, ilgili virüsün Türkiye’ye nereden gelmiş olabileceğini veya bizden nereye sıçramış olabileceğini sol tarafta yer alan harita üzerinden takip edebiliyoruz. Filogenetik ağaç, harita ve aşağıda yer SARS-CoV-2 genom bölgesini analiz ettiğimizde epideminin Çin’den sıçradığı ve ardından diğer ülkelere yayıldığı görülüyor.
Bugün gördüğümüz tabloda Türkiye’de seyahat ile ilişkili virüs girişlerinin sırasıyla İran, Amerika Birleşik Devletleri, Çin, Suudi Arabistan, Kanada, İngiltere, Hindistan, Avustralya, Rusya’dan olduğu görülüyor [3] SARS-CoV-2’nin Türkiye’den birbirinden ayrı olarak gerçekleşen pek çok girişi asıl olarak Suudi Arabistan’dan olduğu ve ağacın her iki yanında, Türkiye’nin farklı illerinden örneklenmiş bir grup vakanın Suudi Arabistan’a seyahat ettiği bildirilmiş durumda (Nexstrain Raporu: 1 Mayıs 2020). Türkiye’de viral örneklerin kapsamlı bir şekilde karıştığını ve kısa bir zaman içinde Türkiye’nin birçok iline ulaştığını varsayabiliriz [4].
Türkiye’nin virüsün yayılımına yönelik analizleri destekleyen SARS-CoV-2 epidemiyolojisi arayüzü Nextstrain altyapısı kullanılarak oluşturulmuş ve “COVID-19 Türkiye Web Portalı” üzerinden de erişime açılmıştır [6,7].
Sonuç
Genom çalışmaları Dünya genelinde hala çok kısıtlı. Bugün toplamda 4,1 milyon üzeri teyit edilmiş vaka olmasına rağmen, sadece 17,747 genom dizini paylaşılmış durumda. Virüsün yayılımı konusunda güvenilir bir tablo görmek için tüm ülkelerin çok daha fazla genom dizisi paylaşması gerekiyor. Türkiye’den ise 63 genom verisi elbette yeterli değil. [3] Daha fazla veri geldikçe COVID-19’un dünyada ve Türkiye’de nasıl yayıldığını net olarak öğrenebiliriz. Ayrıca, yeni mutasyonların tespit edilmesi virüsün genetik yapısına özgü hedefe yönelik bir tedavi stratejisi planlanmasına yardım edebilir.
Genom verilerin virüsün mutasyonların tespit edilmesinde ana rol oynadığını görebiliyoruz. Ancak SARS-CoV-2 virüsü birçok mutasyon geçirmiş olmasına rağmen, henüz COVID-19 hastalığı daha öldürücü veya daha bulaşıcı hale getiren bir mutasyonun varlığına dair kesin bir bulgu yok [4]. Kısacası, tespit edilecek olan yeni mutasyonların, gerek virüsün yayılımı gerek virüsün proteinlerin fonksiyonu ve yapısı üzerinde olumlu veya olumsuz bir etkisinin olup olmadığını belirlemek amacıyla daha fazla genom veri çalışmalarına ihtiyaç vardır. Her ne kadar bir kaç çalışma özellikle virüsün beli gen bölgelerinde tespit edilen mutasyonların virüsün hastalık oluşturma derecesini arttırabileceği yönünde olsa da mutasyonların moleküler düzeyde tanımlanması için elimizde çok daha geniş genom veri setleri olması gerekiyor. Bu bağlamda, önümüzdeki aylarda, farklı ülkelerin yapacağı yeni genom verisi katkıları ile Türkiye’nin bu epidemideki konumunu ve tüm süreci çok daha net anlayacağız.
Genom verilerinden elde edilen her yeni mutasyonun, SARS-CoV-2 virüsünün nasıl yayıldığını ve nasıl hastalık oluşturduğunu anlamak için bir bulmaca parçası gibi kullanılıyor diyebiliriz.
Arta Fejzullahu
Marmara Üniversitesi, Tıbbi Biyoloji ve Genetik AD
İstanbul Aydın Üniversitesi
Notlar/Kaynaklar
[1] Spiteri G, Fielding J, Diercke M, et al. First cases of coronavirus disease 2019 (COVID-19) in the WHO European Region, 24 January to 21 February 2020. Euro Surveill. 2020;25(9):2000178. doi:10.2807/1560-7917.ES.2020.25.9.2000178
[2] Home – PubMed – NCBI. (n.d.). Retrieved from https://www.ncbi.nlm.nih.gov/pubmed
[3] (n.d.). Retrieved from https://www.gisaid.org/
[4] (n.d.). Retrieved from https://nextstrain.org/ncov/global
[5] Hoffmann, M., Kleine-Weber, H., Schroeder, S., Krüger, N., Herrler, T., Erichsen, S., Pöhlmann, S. (2020). SARS-CoV-2 Cell Entry Depends on ACE2 and TMPRSS2 and Is Blocked by a Clinically Proven Protease Inhibitor. Cell, 181(2). doi: 10.1016/j.cell.2020.02.052
[6] SARS-CoV-2 Epidemiyolojisi Arayüzü. (n.d.). Retrieved from https://covid19.tubitak.gov.tr/sars-cov-2-arayuzu
[7] (n.d.). Retrieved from http://sarscov2.adebalilab.org/latest
GitHub birçok insanın bir araya gelip açık kaynaklı yazılım geliştirebilecekleri bir platform. Nextstrain, GitHub (https://github.com/) platformunu kullanmaktadır.
Sarkaç yayın sürecindeki ilgi, geri dönümleri ve değerli katkıları için Bilim Akademisi yayın yönetmeni Defne Üçer Şaylan’a teşekkür ederim.




{kind=link}